 Image: AI generated
Image: AI generated
Legacy Doesn’t Lie
Legacy code has no documentation. If it does, it’s three years old. There are no tests, or if there are, they’re broken and marked skip. The comments contradict the code. The original author has left, and the people who remain only say, “Touch it and it blows up.”
And yet that code is running this very moment. It processes payments, accepts logins, places orders.
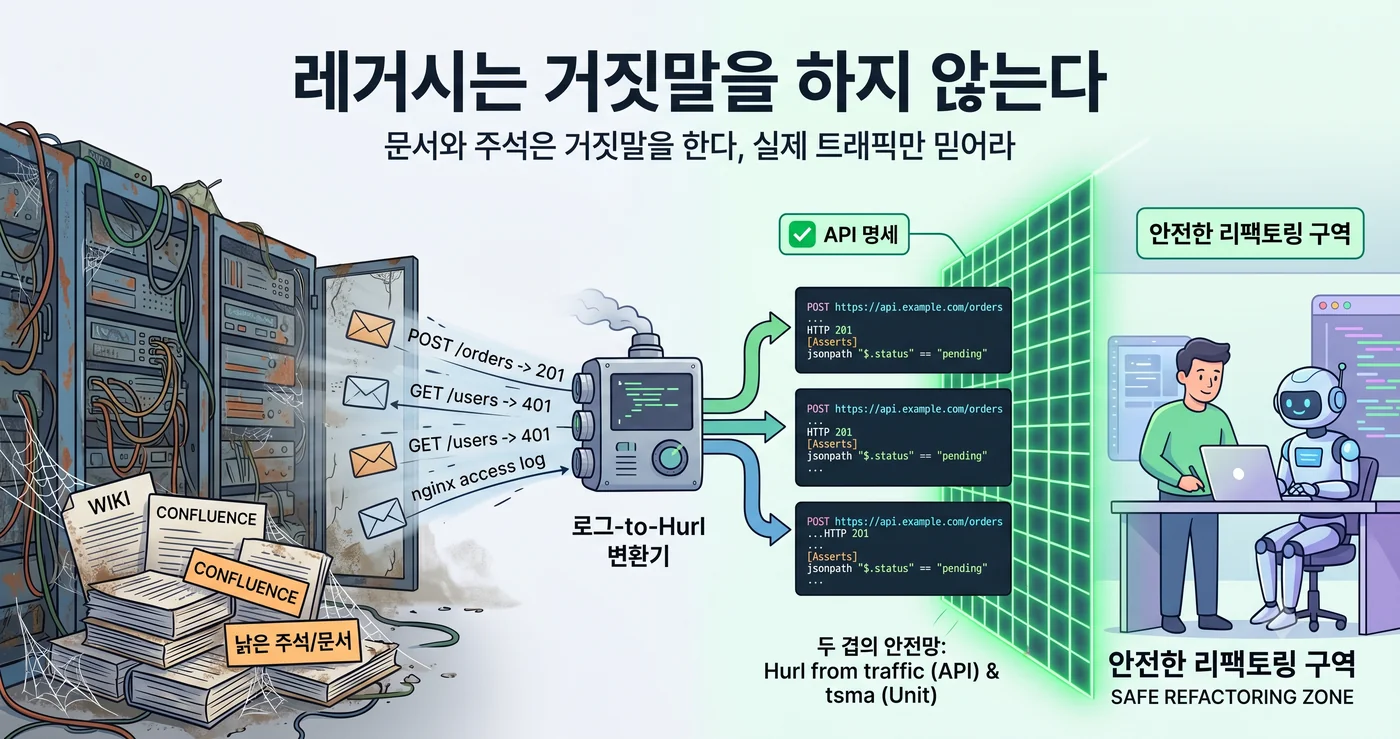
Documentation lies. Comments lie. Human memory lies worse still. The one thing that does not lie is the traffic actually flowing through.
So where do you go to find the spec? Not the wiki. Not Confluence. The nginx access log.
Chicken and Egg
To refactor legacy, you need a safety net. When you change something, you need to know instantly whether the behavior shifted. That safety net is tests.
But legacy has no tests. To write tests, you need to know what the code does. To know what the code does, you need to read it. And when you read it, there are no tests and no docs.
Which comes first, the chicken or the egg? It’s the classic deadlock Michael Feathers named in Working Effectively with Legacy Code. His answer was the characterization test — a test that pins down not what the code should do correctly, but what it currently does, exactly as is. Right and wrong come later. First you must fix the present behavior in place before you can touch anything.
In Feathers’s day, people wrote these by hand. You’d call the function, watch what came out, and type that value straight into expected. Tedious, slow, and so nobody ever finished.
But at the API level, that “result of calling the function” has already been piling up somewhere. Every day, by the tens of thousands. Inside the log files.
A Month of Logs Is the Spec
Collect for a month and you can capture nearly all of a legacy API’s current behavior.
nginx access log (1 month):
endpoint · HTTP method · status code · timing
call frequency → priority
error patterns (401, 422, 500 …)
request/response body (captured via middleware or reverse proxy):
valid request/response pairs → behavior that must pass
error request/response pairs → edge cases that must not break
Combine these two streams and they translate directly into Hurl integration tests. Hurl is a format that writes HTTP requests and expected responses as plain text, exactly as they are. A single pair of traffic — “this request produced this response” — is precisely one Hurl block.
# POST /api/orders — call frequency #3, 12,000/day
POST https://api.example.com/orders
Content-Type: application/json
{ "sku": "A-1024", "qty": 2 }
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.status" == "pending"
jsonpath "$.total" == 49800
This test does not know “how the order API should behave.” It only knows “right now it behaves this way.” That’s enough. The moment refactoring changes this response, the light turns red.
What the log derives automatically:
- Which endpoints are actually used → an endpoint called zero times in a month is dead code. A deletion candidate before refactoring.
- Normal response patterns → the baseline regression tests.
- Error patterns → the real edge cases no human imagines. The 422s and 500s that actual users produced.
- Call frequency → test priority. You pin the 12,000-a-day one first.
That last item matters. When a human writes tests, they start with the happy path they remember. Traffic has no such bias. The path that actually takes the load is the priority.
A Two-Ply Safety Net
This approach isn’t used on its own; it’s one layer of the ratchet pipeline that lifts legacy up to agent-operable.
nginx log (1 month) → Hurl auto-generation → pins the legacy API's current behavior
↓
tsma → function-level safety net (unit)
↓
filefunc → organize code structure (one concept, one file)
↓
refactoring → Hurl verifies API behavior is preserved (integration)
The key is that the safety net has two plies.
- tsma = the function-level safety net. It catches whether internal logic changed. But even if the function signature stays the same, the behavior of the whole endpoint can shift.
- Hurl from traffic = the API-level safety net. It catches whether the contract seen from outside is preserved. However you rip up the inside, as long as what comes in and goes out stays the same, it passes.
Refactoring is by definition “changing internal structure while preserving external behavior.” If so, the definition of the “external behavior” to be preserved must be pinned down somewhere. tsma holds the inner boundary, Hurl the outer. Only when both plies are in place can you tell an agent, “Rip it up however you like; the machine watches what breaks.”
A Judge That Cannot Flatter
This locks in exactly with the essence of the Symbolic Feedback Loop.
Ask an agent, “Did you refactor well?” and it answers, “Yes, I cleaned it up nicely.” Give it an opinion and it flatters. But run Hurl and you get POST /orders → expected 201, got 500. Numbers and status codes cannot flatter. They have no emotions.
A Hurl test pulled from traffic is a spec with no human judgment in it. Not “someone thinks it should behave this way,” but “observation shows it behaved this way.” Not a claim, a measurement. That’s why the rightness or wrongness of a refactor can be judged by a machine, not a person. The LLM is not the judge but the executor, and a deterministic tool renders the verdict.
The Only Premise: Well-Recorded Logs
For this method to hold, you need exactly one thing. A month of well-recorded logs.
Here “well-recorded” is everything. The access log alone isn’t enough. It gives you the endpoint, the status code, and the timing, but not the core thing to pin down — the pair of request body and response body. Knowing only POST /orders → 201 won’t let you reproduce “this input produced this output.” To fix a feature in place, you must hold both what went in and what came out.
So the real question is not “how do I write the tests” but “are my logs written well enough to be a spec.”
- Are request/response bodies kept, or only status codes?
- Are error responses kept too? The bodies of 422s and 500s are precisely the edge cases no human imagines.
- Are the logs structured so a machine can pair requests with responses?
If this is in place, you’ve already been writing the spec for a month. There’s no need to write separate tests. The log pipeline has been writing them for you. If it’s not in place, just slip in one layer of middleware and leave it on for a month. A month later, the entire current behavior of the legacy lands in your hands.
Why a month and not a day? A day captures only the happy path. A month captures the end-of-month batch, the traffic surge right before settlement, the admin endpoints called only rarely, the cron that runs once at 3 a.m. — the long tail of the system. A spec is not an average but a distribution.
Translate Logs into Hurl to Pin Features in Place
Once the logs are in place, the rest is mechanical. Feed a month of request/response pairs into a tool, and translate each pair into a Hurl block. The hundreds of Hurl files that pour out are the characterization suite — a safety net that pins down the whole current behavior of the legacy. You read not a single line of code. You read only the traffic that flowed by.
Let me preempt the point where people usually hesitate. “The logs contain PII, payments, tokens — is it okay to pin that into tests?”
It is. More precisely, there’s no need to pin it. This methodology never needed the values in the first place. What a characterization test fixes is not the value but the behavior.
HTTP 201
[Asserts]
jsonpath "$.order_id" exists
jsonpath "$.total" == 49800
What matters here as a spec is not the number 49800 but the structure: “the total field exists as an integer, and for a given input it is computed this way.” Mask the values or swap in synthetic data and the spec loses almost none of its worth. capture → masking → Hurl generation — this entire pipeline runs inside your own infrastructure. The raw logs never go anywhere. What remains is a spec with the values hidden, a contract that preserves only the structure. That you don’t have to send the logs outside is not a security concession but the essence of this approach — because all you ever needed was to pin the behavior.
Run the generated Hurl against staging once, and pass/fail splits on the spot. If all the lights turn green, you can begin refactoring. Tell the agent to rip it up however it likes, and let Hurl watch what breaks.
A Ladder Laid Without Code
So the real value of this approach is not “you write tests fast.” The real value is this.
- It starts without reading the code — the original author is gone and there are no docs, but the traffic alone lays the safety net. You earn the right to touch the code before you understand it.
- The result is immediately verifiable — run the generated Hurl against staging and pass/fail comes out on the spot. Not “it’ll probably work” but “right now 327 of 327 pass.”
- The data never clears the fence — from capture to Hurl generation, it all finishes inside your own infrastructure. The more regulated the industry, the more decisive it is that you can start without sending anything outside.
The first dig of legacy modernization usually stalls at the cliff of “nobody knows what the current behavior is.” Traffic → Hurl lays a ladder against that cliff. Laying the ladder needs no code. The traffic that flowed by is enough — and even that traffic stays inside the fence.
The Flow Was Already Writing the Spec
We strain to write the spec separately. We hand-write OpenAPI, describe behavior in the wiki, and when those diverge from the code we call it drift and lament.
But a living system has been writing its own spec every moment. Each time a request comes in and a response goes out, that is a one-line self-description: “I am this kind of system.” The log file is that autobiography accumulated over a month.
We just didn’t read it.
Legacy isn’t missing documentation. The documentation is inside the access log; it’s only that the format is inconvenient for humans to read. Translate it into Hurl and it becomes a runnable spec, a contract the machine adjudicates.
Documentation lies. Traffic does not lie.
Related Articles
- Hurl Stops Drift — How to declare HTTP contracts in plain text and lock them into CI. If this article is “traffic → Hurl,” that one is “locking drift with Hurl.”
- tsma — A Regression Defense Line for Legacy Code — The inner boundary of the two-ply safety net (function level). If Hurl is the outer boundary, tsma is the inner.
- Agent Operable Codebase — The three-stage pipeline that lifts legacy into code an agent can work on.
- Why Coding Agents Work and Why They Break — The structure of the Symbolic Feedback Loop.
- Constraints Are Contracts — Tests as verifiable, enforceable contracts.
- How to Rescue Failed Vibe Coding — A hands-on lecture on using characterization testing to diagnose → lock → repair → extract → migrate legacy.
Further Reading
- Michael Feathers, “Characterization Testing” — A piece by the coiner of the term. “The moment software goes into production it becomes its own specification.” Nearly the same thesis as this article’s title.
- The official Hurl tutorial, “Your First Hurl File” — From
GET / HTTP 200to--testmode. A hands-on introduction to the idea that one line of plain text is a test. - GitHub Engineering, “Scientist: Measure Twice, Cut Once” — A library that runs legacy (control) and new (candidate) code simultaneously in production and compares the results. “Only real behavior is the true spec.”
- Twitter Diffy (InfoQ summary) — A proxy that sends the same request to old and new services and catches only the response difference as a regression. The classic precedent of “pin behavior without writing tests.”
- GoReplay — A tool that captures live HTTP traffic from a network interface and replays it into staging. The flagship implementation of “production traffic as test input.”
- Nicolas Carlo, “Characterization vs Approval Tests” — Sorts out three terms for what is essentially the same technique, and emphasizes the role of the “Printer” that scrubs sensitive data from output.
- Pact — Consumer-driven contract testing. An “explicit contract” approach contrasted with pinning traffic. Seeing both together brings balance.
Sources / Evidence
Core concepts and tools
- Michael Feathers. Working Effectively with Legacy Code. Prentice Hall, 2004. — The origin of the characterization test concept. “Pin down not what the code should do correctly, but what it currently does.”
- The Hurl project (hurl.dev) — A plain-text HTTP request/response test format. Integrated as one of yongol’s 10 SSOTs.
- tsma’s 527-function demonstration — the function-level ratchet (tsma).
Carving tests out of traffic and execution (carving / record-replay)
- Elbaum, Chin, Dwyer, Jorde (2009). “Carving and Replaying Differential Unit Test Cases from System Test Cases.” IEEE TSE 35(1). — The academic foundation of differential unit tests that record a system execution and replay it at the unit level.
- Meta Engineering Team (2024). “Observation-based Unit Test Generation at Meta.” FSE 2024, arXiv:2402.06111. — Carving tests from observed values of app execution. 9.6 million runs in CI, 5,702 defects detected. Industrial-scale proof of “observation is the test.”
Pinning current behavior in place (snapshot / golden master)
- Fujita, Kashiwa, Lin, Iida (2023). “An Empirical Study on the Use of Snapshot Testing.” ICSME 2023. — Empirical study of snapshot (= golden master / characterization) test adoption. “Fix not correctness but the current output to detect changes.”
Refactoring safety net
- Kim, Zimmermann, Nagappan (2014). “An Empirical Study of Refactoring Challenges and Benefits at Microsoft.” IEEE TSE 40(7). — Evidence that without tests to guarantee behavior preservation, refactoring is a cost and a risk.
- Yoo, Harman (2012). “Regression Testing Minimization, Selection and Prioritization: A Survey.” STVR 22(2). — Regression testing = the standard definition of “confidence that changes don’t harm existing behavior.”
Real usage distribution is the priority
- John D. Musa (1993). “Operational Profiles in Software-Reliability Engineering.” IEEE Software 10(2). — Allocate tests by usage frequency, and even if you stop on schedule, the most-used features are the most verified. The classic foundation of “traffic distribution instead of happy-path bias.”
Why a machine must render the verdict (the LLM is not the judge but the executor)
Huang, Chen, Mishra, et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024, arXiv:2310.01798. — Without external feedback, LLMs cannot correct their own reasoning. Why a deterministic external verifier is needed.
Sharma, Tong, et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024, arXiv:2310.13548. — RLHF trains agreement, collapsing the reliability of LLM self-judgment.
Cover image: AI-generated (Google Gemini)