 Image: AI generated
Image: AI generated
It rises again from the very place you fixed
I built a tool that closes drift.
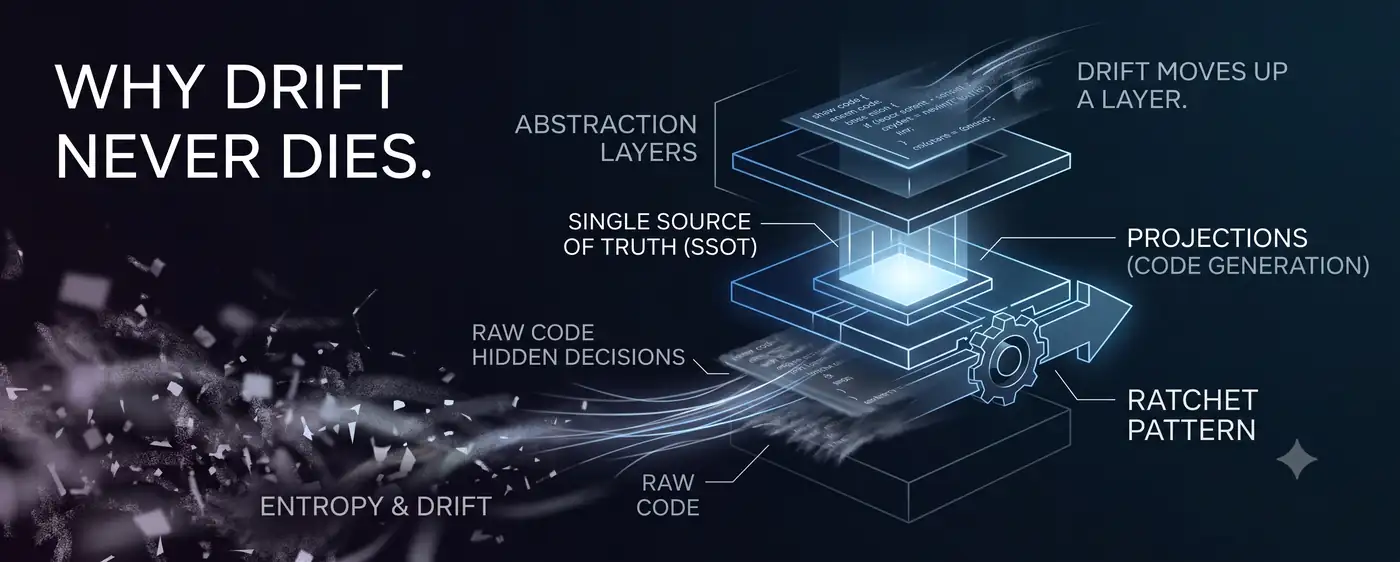
The thesis of yongol is simple. Decisions that don’t live in a single authoritative source (SSOT) drift. So I put decisions in the SSOT and turned code into disposable projection – redrawn from scratch on every generation. The kind of business-logic drift where a column declared BIGINT silently reverts to INT after a single refactor: that was closed.
Then, not long ago, I was analyzing a batch of defects in code generated by yongol, and I noticed something strange. The defects were confessing themselves in the same sentence structure. “import collection is decoupled from ‘does the handler actually use time’.” “requiredness inference is decoupled from ‘does the target API actually require this parameter as required’.” Path parameters are always required; imports only when the token is actually used. The same structural decisions were embedded in the generator code as convenient local proxies, recorded in no SSOT.
Drift hadn’t disappeared. It had climbed one layer up. Business logic was closed by the SSOT, but the generator itself – the thing that reads the SSOT and stamps out code – had no SSOT for its own structural decisions. yongol’s thesis had come back to haunt yongol itself. At precisely the spot the theory predicted.
So the question changes. Everyone knows why drift occurs. The real question is this: why does it keep coming back even after you fix it?
The root: decisions and details are different things
Let’s rebuild from physics.
A decision is information. Low-entropy information, at that. “This column must be 64-bit” is one state deliberately selected from a vast number of possibilities. Nature abhors low entropy. Left alone, information bleeds into the surrounding noise and vanishes. The second law of thermodynamics applies to decisions too.
Software engineering has observed this decay for a long time. Lehman’s laws of software evolution state that the complexity of an E-type system increases unless explicit effort is made to reduce it (1980). Information physics goes deeper. Landauer showed in 1961 that even erasing a single bit incurs a minimum thermodynamic cost (kT ln 2). Altering and retaining information is not free in principle. Keeping a decision in place requires continuous expenditure of energy.
For information to survive, two things are needed: an authoritative store and active re-projection from it – error correction, ceaselessly redrawing. DNA in our bodies works this way. Parity bits in digital storage work this way. You keep the original separate and restore from it every time.
Drift happens when this restoration breaks down. The mechanism is singular. I call it proxy binding. When the medium fails to distinguish and preserve decisions from details, the next person (or the next agent) cannot read the decision from the authoritative source and instead re-derives it from a convenient correlated signal nearby. “This column is timestamptz, so I should import time” – that kind of guess. Usually correct. That’s why it’s dangerous. Occasionally wrong, and when wrong, the decision vanishes silently.
raw code is exactly that kind of medium. Code doesn’t mark the distinction between “this is a decision” and “this happens to be true here by coincidence.” That’s why throwing a bigger model at it doesn’t solve it. When the medium itself can’t carry decisions, it doesn’t matter how smart the reader gets – there’s nothing to read.
This phenomenon hasn’t gone unnamed. In software architecture, Perry and Wolf distinguished between erosion – violating principles – and drift – growing numb to the architecture (1992). Cunningham called the interest accruing on poorly written code technical debt (1992). Across fields, the symptoms have been well named. What I’m adding is the single mechanism underneath (proxy binding), and the observation that this mechanism recurses upward every time you close a layer. I’m asking about causation, not labels.
Why it climbs upward
Up to here, this is a known story. What’s new comes next.
Closing drift requires two things: a store that holds decisions authoritatively (an SSOT) and a closing agent that reads it and stamps out artifacts (a generator). But the closing agent itself also makes decisions. Structural decisions like “path parameters are treated as required.” The medium where those decisions live – the generator’s code – also fails to distinguish decisions from details.
The same mechanism repeats one layer up. The very act of closing creates an unclosed medium one layer above. Drift hasn’t been eradicated – it has moved. Into a layer without authority.
Push this to its logical end and an uncomfortable conclusion emerges. Give the generator an SSOT? Whatever builds that SSOT will again embed its own decisions in an unclosed medium. With each layer you climb, the surface area shrinks, but at the top there always remains a layer without authority. Whether that’s a human, or a generator of generators. Drift is asymptotically ineradicable. (This is more a strong conjecture than a proof. But every layer I’ve closed so far opened the layer above at the moment of closing.)
This is the answer to “why does it keep coming back.” It doesn’t come back. When we close one layer, the tool that closes it opens the next. The same river, leaking through a higher levee.
The asymmetry of remedies: what can be declared versus what can only be verified
So how do you close the upper layer? Here, a decisive asymmetry reveals itself.
Business logic decisions are usually values. The column is 64-bit, access is owner-only, pagination is cursor-based. Values can be declared. Write them in DDL, in OpenAPI, in a spec file, and that becomes the SSOT. Closed by declaration.
A generator’s structural decisions are different. “Path parameters are required,” “imports are bound to actual token references,” “required (key exists) and non-empty are different things.” These are not values but behavioral properties of a function across all inputs. Behavioral properties cannot be enumerated by declaration. Because the inputs are infinite. There is no way to write in a YAML field: “this transformation must behave this way in all cases.”
So decisions at this layer can only be closed not by declaration but by verification. Type checkers, property tests, compilation gates. Not pinning decisions as data, but pinning them as checkpoints where machines catch violations every time.
This is the point I made in another article when I wrote “codify human review.” Some promises can be declared, and SSOT keeps them. Some promises cannot be declared, and gates keep them. Whether the code a generator stamps out compiles cannot be written into any SSOT. It can only be confirmed by running the compiler every time. Without that checkpoint, the promise “successful generation = buildable output” floats outside the architecture, and artifacts break even when validate passes 0/0.
Close declarable drift with SSOT. Close drift that can only be verified with gates. Confuse the two, and you’ll be playing whack-a-mole with declarations forever.
Same river, different levees
This structure repeats beyond code.
In knowledge, drift is the loss of provenance. When a claim loses who made it, when, and on what grounds, that claim bleeds into the noise of “fact.” The next person can’t read from authority (the original source) and re-derives from surrounding context. This is why I designed GEUL as a language that forcibly attaches provenance, timestamp, and confidence to every piece of information. The epistemology that there are no facts, only claims, is a safeguard against proxy binding in the knowledge layer.
In law, drift is precedent straying from the original decision. Civilization closed this not by trusting the judge’s conscience on every case, but by codifying rules, defining violations, and attaching enforcement mechanisms. A good judge is not the SSOT – a good judge is a proxy. Statutory law is the SSOT.
Same river. If a decision doesn’t live in an authoritative place, if the medium can’t distinguish decisions from details, it drifts. Code, knowledge, or law.
Conclusion: not eradication, but pushing upward
The fight against drift cannot aim for eradication. Eradication is impossible. Because the tool that closes always opens the next layer.
The goal is something else. Push drift upward into higher layers with smaller surface area, and arm those layers with mechanical verification. Gather decisions that were scattered across tens of thousands of lines of raw code into a single SSOT, and the surface that can drift shrinks dramatically. The remaining surface – the generator’s behavioral invariants – is blocked by gates. Even so, at the very top remains the last layer with nowhere left to delegate: human judgment. There, we verify anew each time and pin the promises again.
This is the ratchet. It turns in one direction only. A tooth that has clicked up does not slide back down. Entropy tries to pull decisions down, and the ratchet clicks them back up one notch at a time. There is no equilibrium. Stop, and you drift.
Drift never dies. And so we never stop. Building promises against entropy is not a single victory – it is a permanent ratchet.
Related Posts
- Ratchet Pattern – How to Make an Agent Follow Through
- Why Your Agent Loop Diverges
- Reins Engineering – AI with Reins
Further reading (external)
- Lehman’s laws of software evolution – Overview of the empirical laws that software grows complex without active intervention.
- Landauer’s principle – The thermodynamic cost of erasing information.
Sources
- Perry, D. E. & Wolf, A. L. (1992). Foundations for the Study of Software Architecture. ACM SIGSOFT Software Engineering Notes, 17(4), 40-52. ACM – The distinction between erosion and drift.
- De Silva, L. & Balasubramaniam, D. (2012). Controlling software architecture erosion: A survey. Journal of Systems and Software, 85(1), 132-151. ScienceDirect
- Lehman, M. M. (1980). Programs, Life Cycles, and Laws of Software Evolution. Proceedings of the IEEE, 68(9), 1060-1076. IEEE – The law of increasing complexity and the law of continuing change.
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183-191. IBM – The minimum thermodynamic cost of information erasure.
- Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27, 379-423. DOI – The foundation of information, entropy, and error correction.
- Cunningham, W. (1992). The WyCash Portfolio Management System. OOPSLA ‘92 Experience Report. c2.com – Technical debt and “the interest on poorly written code.”