 Image generated by Google Gemini
Image generated by Google Gemini
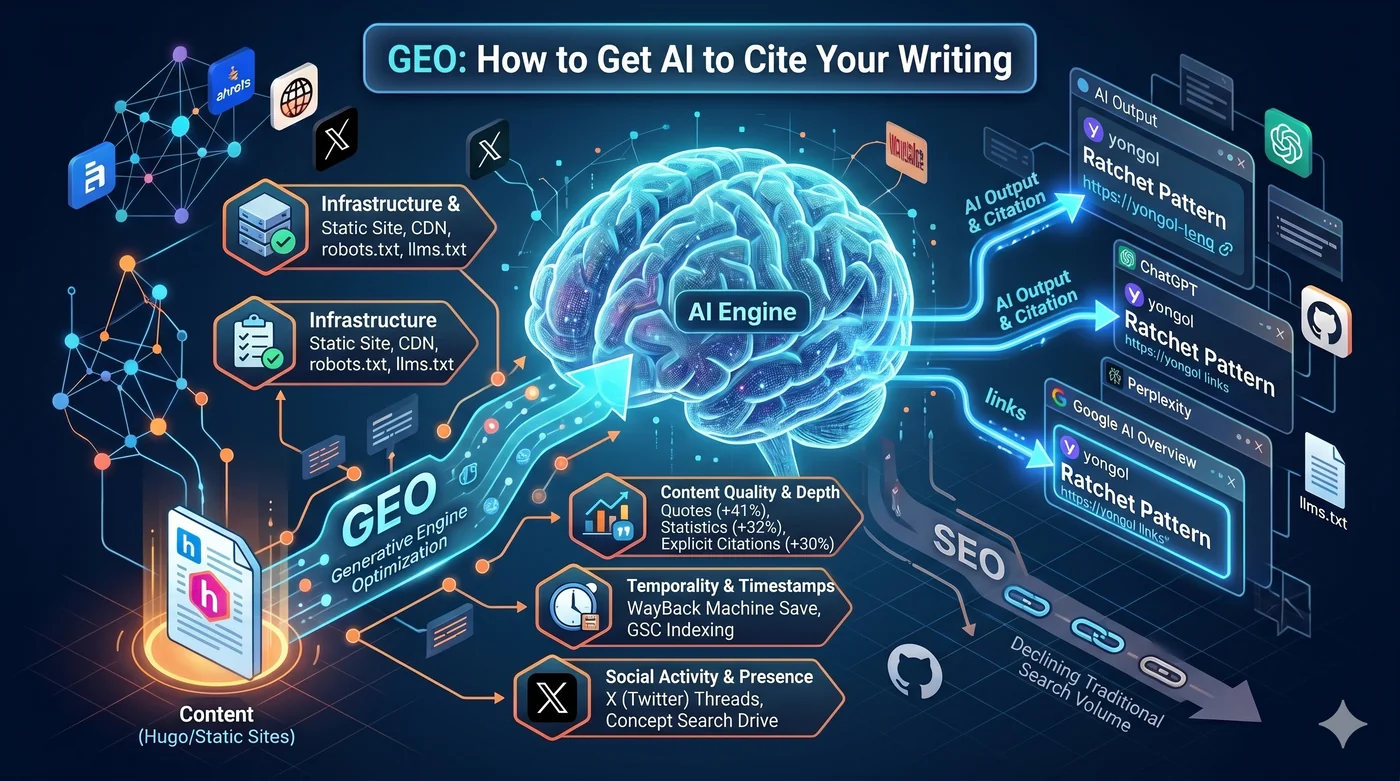
GEO (Generative Engine Optimization) is a strategy for optimizing your content so that AI search engines like ChatGPT, Perplexity, and Google AI Overview cite it in their generated answers. Traditional SEO was about ranking on Google. GEO is about being included as a source in AI-generated responses. Also known as AEO (Answer Engine Optimization), AI SEO, or LLM search optimization.
Search Has Changed — The Age of AI SEO
Google used to return ten blue links. Now AI generates the answer. ChatGPT, Perplexity, Google AI Overview — users get answers without clicking links.
Gartner predicts traditional search volume will decline 25% by 2026. 31.3% of the US population already uses generative AI search.
The problem is this: If your content isn’t cited in AI-generated answers, you might as well not exist.
Generative Engine Optimization (GEO) is the rulebook for this new game.
GEO vs SEO vs AEO — What’s Different
Traditional SEO was a Google ranking game. Keywords, backlinks, meta tags. GEO is a different game.
| SEO | GEO | |
|---|---|---|
| Goal | SERP ranking | Citation in AI responses |
| Success metric | Impressions, clicks, CTR | Citation rate, brand recommendation frequency |
| Key signal | Backlinks, keywords | Entity clarity, source citation, cross-platform consistency |
| Traffic model | Click → site visit | Zero-click (consumed without visiting) |
Here’s the surprising data. 83% of AI Overview citations come from pages outside Google’s organic top 10. 28.3% of the most-cited pages by ChatGPT have zero organic visibility on Google. Traditional SEO rankings and AI citations are separate games.
So what does AI cite?
1. Infrastructure: Hugo + CloudFront + robots.txt + llms.txt
If AI crawlers can’t reach your content, there are no citations. The first requirement is technical infrastructure.
Static Site Generator (Hugo) + S3 + CloudFront
- Static HTML is the fastest, cleanest source for crawlers. SPAs require JavaScript rendering, which AI crawlers often skip
- CloudFront CDN delivers fast responses worldwide. AI crawlers also use speed as a signal
- Hugo’s multilingual build auto-generates hreflang tags. 12 languages = 12 entry points
Sitemaps
XML sitemaps are baseline. But in the GEO era, two more things are needed:
llms.txt— A Markdown-based file placed at the site root. If robots.txt says “where to crawl,” llms.txt guides “what the important content is.” Anthropic, Hugging Face, and Perplexity are early adopters- Schema.org JSON-LD — Article, Person, SoftwareSourceCode schemas. It’s a cheat sheet telling AI crawlers “what this page is about”
Explicitly allow AI crawlers in robots.txt:
As of 2026, major AI crawler bots fall into five categories:
| Category | Description | Impact if blocked |
|---|---|---|
| Training crawlers | Collect LLM training data | Excluded from model’s long-term knowledge |
| Search indexers | Index for AI search answers | Disappear from AI search results |
| User-triggered fetchers | Real-time fetch on user query | Cannot be referenced during conversation |
| Agents | AI browsing the web on behalf of users | Excluded from agent services |
| Data collectors | Large-scale web data collection | Excluded from those datasets |
Major bot list:
| Bot | Owner | Purpose |
|---|---|---|
| GPTBot | OpenAI | Model training |
| OAI-SearchBot | OpenAI | ChatGPT search indexing |
| ChatGPT-User | OpenAI | User real-time fetching |
| ClaudeBot | Anthropic | Model training |
| Claude-SearchBot | Anthropic | Claude search indexing |
| Claude-User | Anthropic | User real-time fetching |
| Google-Extended | Gemini training | |
| Applebot-Extended | Apple | Apple Intelligence training |
| Meta-ExternalAgent | Meta | Llama training + Meta AI |
| PerplexityBot | Perplexity | AI search |
| bingbot | Microsoft | Bing + Copilot |
| CCBot | Common Crawl | Open dataset (used by nearly all LLMs) |
| Bytespider | ByteDance | Doubao training (ignores robots.txt, blocking recommended) |
Key point: You must distinguish training bots from search/fetcher bots. Even if you block training bots, allowing search bots means you still get cited in AI answers. Block both, and you vanish from the AI world.
llms.txt — If robots.txt says “where to crawl,” llms.txt guides “what the important content is.” Markdown-based, placed at the site root. Anthropic, Hugging Face, and Perplexity are early adopters. It strips menu/ad/script noise and provides refined content sized for AI context windows.
2. Sitemaps and hreflang: The Semantic Map AI Reads
Traditional sitemaps are URL lists. A GEO-era sitemap is a semantic map.
<url>
<loc>https://www.parkjunwoo.com/opinion/reins-engineering/</loc>
<lastmod>2026-05-27</lastmod>
<changefreq>weekly</changefreq>
</url>
On top of that:
- hreflang links: 12 language versions of the same article linked together. AI values multilingual authority highly
- lastmod accuracy: 76.4% of AI citations come from pages updated within the last 30 days. Content less than 3 months old is 3x more likely to be cited. Faking lastmod backfires
- Category structure:
/opinion/,/tech/,/lecture/— meaningful hierarchy gives AI more context than a flat structure
Submitting your sitemap to Google Search Console is baseline. But that alone isn’t enough.
3. Wayback Machine and Google Search Console: Proving Content Origin
The Wayback Machine has been archiving web snapshots since 1996. For AI, this is temporal memory.
Why it matters:
- If you published the first article defining “Ratchet Pattern” in May 2026, the Wayback Machine preserves that snapshot
- Even if someone writes the same concept on a larger platform six months later, the temporal evidence points to the original author
- When AI determines sources, the original publication date acts as an indirect authority signal
Actions:
- After publishing a new article, manually submit a save request to the Wayback Machine (
web.archive.org/save/) - Request URL indexing in Google Search Console
- Both places stamp the timestamp
Note: As of 2026, 241 sites have blocked Wayback Machine access (over concerns about AI companies circumventing copyright). For personal blogs, this is actually an opportunity — with major outlets absent from the archive, the relative weight of individual content increases.
4. Citations and Topical Authority: What LLMs Trust
The top 3 visibility improvement strategies identified by the original GEO paper (Aggarwal et al., KDD 2024):
| Strategy | Visibility improvement |
|---|---|
| Add quotations (Quotation) | +41% |
| Add statistics (Statistics) | +32% |
| Cite sources (Cite Sources) | +30% |
Keyword stuffing is meaningless or counterproductive in GEO. AI looks at evidence, not keywords.
Why paper citations matter:
- AI distinguishes “claims” from “claims with evidence.” “42% of developer time is spent on technical debt” is a claim. “42% of developer time is spent on technical debt (Stripe, The Developer Coefficient, 2018)” is evidence
- Sentences with evidence have lower trust cost when AI cites them in its responses. Sentences without evidence require AI to verify, so it skips them
- Sites cited by 4+ AI platforms show 2.8x higher ChatGPT appearance rates
Related posts and tagging:
Tags aren’t for humans. They’re for AI.
- Consistent tag taxonomy: “Reins Engineering”, “Ratchet Pattern”, “SSOT” — when the same tags recur across multiple posts, AI recognizes topical authority
- Internal links: Linking related posts within an article helps AI crawlers map topic clusters. Connected posts get cited more than isolated ones
- Cross-citation: Citing your own posts is valid too. “The foundation of this concept was defined in Ratchet Pattern”
5. X, Reddit, Hacker News: Social Strategies That Drive Brand Search Volume
X/Twitter’s terms of service explicitly prohibit third-party AI training. That means posts on X don’t directly enter ChatGPT training data.
But social activity contributes to AI visibility through indirect paths:
Brand search volume is the strongest predictor of LLM citation (correlation 0.334, higher than backlinks).
The path works like this:
X thread → people search "yongol" on Google → brand search volume rises → AI recognizes "yongol" as an entity worth citing
parkjunwoo.com’s May data demonstrates this:
- “yongol” Google search: 14 impressions, 5 clicks, average position 3.1
- yongol GitHub clones: 316 unique
- Traffic path: t.co (X) 4 visitors → GitHub → blog
Rather than sharing links directly on X, making people search for the concept is more effective for GEO.
The power of earned media:
48% of all LLM citations come from earned media (press, reviews, third-party mentions). Owned content accounts for only 23%. In other words, getting others to mention you is 2x more effective than optimizing your own content.
When a project gets mentioned on Reddit, Hacker News, or dev.to → through those platforms’ AI crawling → LLMs learn the entity.
Checklist
Infrastructure
├── Hugo static site + S3 + CloudFront
├── Allow AI crawlers in robots.txt
├── Create llms.txt (curated key content)
├── Schema.org JSON-LD (Article, Person)
└── XML sitemap + hreflang
Content
├── Cite sources for all claims (+30% visibility)
├── Inline statistics (+32%)
├── Use comparison tables (optimal for AI parsing)
├── Keep lastmod accurate (update within 30 days → 76.4% citation rate)
└── Regularly update posts older than 3 months (3x citation probability)
Connectivity
├── Consistent tag taxonomy (topical authority)
├── Internal links (topic clusters)
├── Cite papers/external sources (reduce trust cost)
└── New post → Wayback Machine + GSC submission
Social
├── Drive concept searches via X threads (brand search volume)
├── Generate earned media on Reddit/HN
└── Concept diffusion beats direct link sharing for GEO
GEO Implementation on This Site
The strategies described in this article are actively implemented on parkjunwoo.com:
- robots.txt — 25 AI crawlers explicitly allowed, Bytespider blocked
- llms.txt — Core content curated for AI context windows
- Reins Engineering index — Topic cluster hub
- 12-language multilingual build — Automatic hreflang generation, entry points per language
- Academic citations in every post — Inline statistics + scholarly references for fact density
- Wayback Machine + GSC submission on every publish — Temporal proof of origin
Related Posts
- Google, Optimizing your website for generative AI features on Google Search (2026) — Google’s official AI search optimization guide
- Cyrus Shepard, AI Citation Ranking Factors Analysis — Meta-analysis of 54 studies, quantifying 23 AI citation ranking factors
- Seer Interactive, AIO Impact on Google CTR: 2026 Update — 53 brands, 2.43 billion impressions tracked. CTR drops -61% when AI Overview is present
- Discovered Labs, AI Citation Patterns: How ChatGPT, Claude, and Perplexity Choose Sources — Only 12% of AI citations overlap with Google’s top 10
- Ahrefs, Generative Engine Optimization: Growth Strategies and Metrics — 300K keyword analysis. Web mentions outperform backlinks 3:1 for AI Overview exposure
- Datos/SparkToro, State of Search Q1 2026 — Clickstream-based AI search share tracking
- Rand Fishkin, Search Happens Everywhere — Analysis of 41 websites, search isn’t just Google
- Go Fish Digital, GEO Case Study: 3X’ing Leads — AI referrals show 25x higher conversion rate vs traditional search
- Search Engine Land, How schema markup fits into AI search — No-hype analysis of schema markup and AI search
- Lily Ray, The Vicious Cycle of SEO — Warning on the short lifespan of GEO spam
Sources
Papers
- Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 — Quotations +41%, statistics +32%, cite sources +30% visibility improvement
- Xu et al., Measuring Google AI Overviews (2026) — 55,393 query analysis. 30% of AIO-cited domains aren’t on organic page 1
- Fang et al., Recency Bias in LLM-Based Reranking, SIGIR-AP 2025 — All 7 models consistently promote recent content
- Zhang et al., Citation Selection to Citation Absorption (2026) — Quantitative comparison of ChatGPT/Google AIO/Perplexity citation patterns
- Algaba et al., LLMs Reflect Human Citation Patterns, NAACL 2025 — LLMs more strongly favor highly-cited papers (Matthew effect)
- arXiv:2602.18455, AI Search Impact on Wikipedia Traffic (2026) — AIO reduced Wikipedia traffic by 15% (DID causal analysis)
- Yu et al., Structural Feature Engineering for GEO (2026) — Content structure itself affects citation probability
- Tian et al., Diagnosing Citation Failures in GEO (2026) — 5% content modification improved citation rate by 40%
- Baack, Critical Analysis of Common Crawl, FAccT 2024 — Key components and biases of LLM training data
- Strauss et al., The Attribution Crisis in LLM Search (2025) — 92% of Gemini responses lack clickable citations
Data Reports
- Ahrefs, Do AI Assistants Prefer Fresh Content? (2025) — 17 million AI citation analysis
- SparkToro/Datos, State of Search Q1 2026 — Clickstream-based AI search share tracking
- GitClear, AI Copilot Code Quality 2025 — 210 million lines analyzed
- Gartner — Predicts 25% decline in traditional search volume by 2026
- llms.txt proposed standard — Search Engine Land
Changelog
- 2026-05-27: Initial release