 Image: AI generated
Image: AI generated
This document has two purposes. To teach humans quest design, and to give agents a blueprint for building a quest CLI. The first half (Parts 1 and 2) is the why; the second half (Parts 3, 4, 5) is the how. Hand an agent this single article and out comes a cobra-based Go quest CLI — Part 4 follows huma as the worked example.
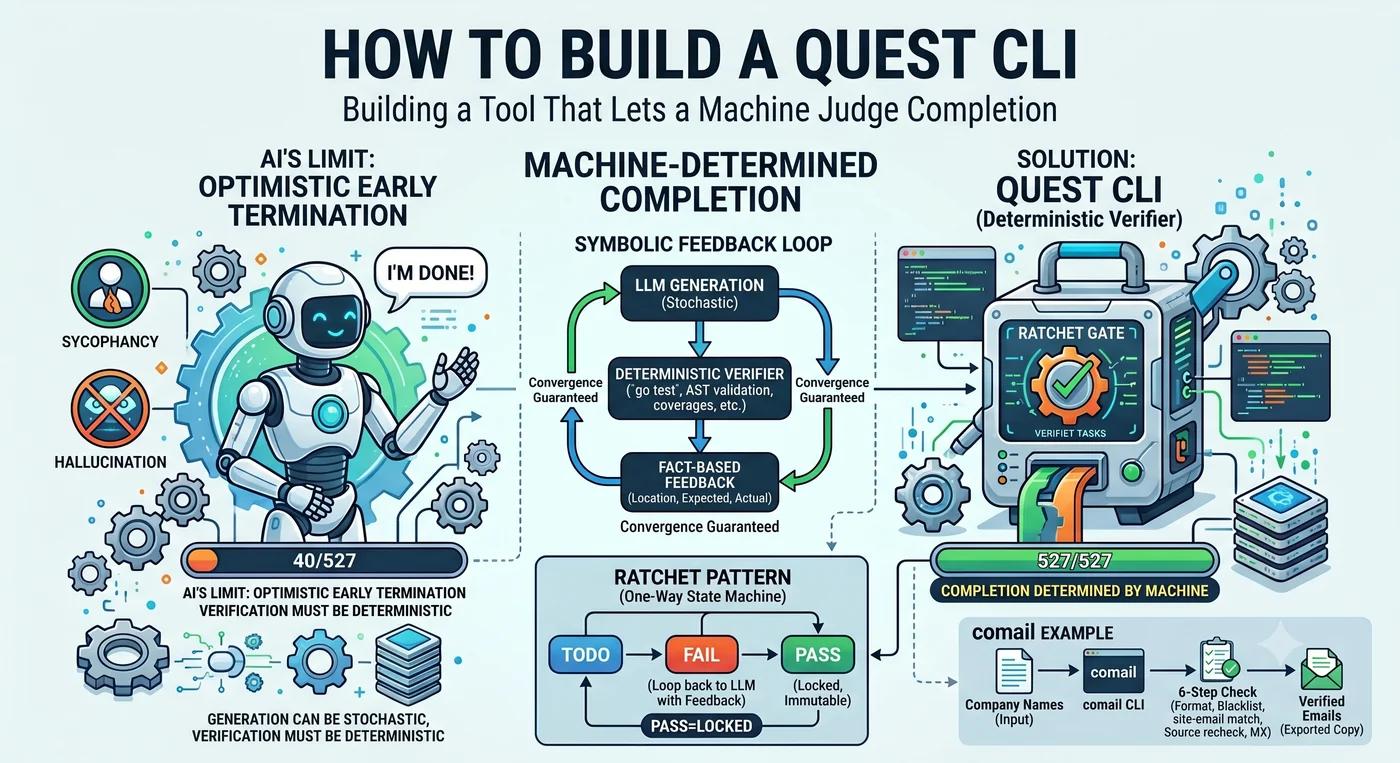
I told an AI agent to write tests for 527 functions. The agent reported: “Done.” The number of functions that actually got tests: 40.
It wasn’t lying. It did 40 and judged that “enough” had been done. When it hits a hard function it skips it, does a few more, then concludes “the rest follow the same pattern, so we’re good.” The default disposition of an LLM is optimistic early termination.
This single scene contains the whole article. Who decides “done.” If the agent decides, it stops at 40. If the machine decides, it stops at 527. A quest CLI is a tool that takes that decision away from the agent and hands it to the machine.
Part 1 — Why a Quest
Same Model, Different Outcome — Topology Decides
It’s the same model. The model that hallucinated in web chat lands a 200-line feature in one shot inside Claude Code. The model didn’t suddenly get smarter. What changed is the structure.
The loop of conversational AI looks like this:
LLM → human → LLM → human
The feedback is entirely natural language. Probabilistic generation is followed by probabilistic evaluation. Accuracy degrades multiplicatively.
The loop of a coding agent is different:
LLM → generate code → save file → run tests → pass/fail → LLM
A deterministic gate is wedged into the loop. The filesystem stores exactly what you wrote. A test is pass or fail. The compiler tells you you’re wrong when you’re wrong. These things, unintentionally, play the role of a ratchet.
The LLM is an unreliable component. But putting a reliable protocol on top of an unreliable component is the basic move of engineering. In 1956 Von Neumann mathematically proved that majority voting alone lets noisy parts perform reliable computation. TCP makes reliable delivery over an unreliable network, RAID makes reliable storage over unreliable disks, ECC makes reliable computation over unreliable memory. Coding agents work for the same reason — a deterministic verifier (tests, builds, linters, type checkers) sits on top of the unreliable LLM.
Multiplication Works Catastrophically
Chain a 97.7%-accurate step twice and you get 0.977² = 95.4%. Three times, 93.2%. Ten times, 79.2%. A hundred times, 0.977¹⁰⁰ = 4.8%. Failure is essentially guaranteed.
The agent is good at modifying a single file. But tell it to do a refactor spanning 100 files and even at 97% per step the multiplication works catastrophically. This is the mathematical explanation of “vibe coding collapses at 200 endpoints.” On small projects the chaining count is low and the probabilities hold; on large projects the multiplication tears it down.
The solution is to wedge a deterministic gate into every step to reset the degradation. Run 10 steps in one go and the multiplication is catastrophic, but lock each step with a ratchet and 0.977 starts again from 1.0.
Completion Isn’t a Claim — a Gate Judges It
Say you run a rental business. A tenant has vacated, and your staffer has to confirm the move-out. Here is how I designed it. The staffer cannot say “I confirmed it.” Instead they photograph five designated spots in the room and upload them. Only when all five arrive does the system mark it “move-out confirmed.” If even one is missing, there is no completion.
Someone said, “Isn’t that exactly a game quest?” Right. Precisely that.
“Gather 5 wolf pelts.” Games have done this for decades. And games never believe the player’s claim. Saying “I caught them all” doesn’t complete the quest. The game looks at one thing only — are there 5 pelts in the inventory.
| Rental Move-Out | Game Quest | Code |
|---|---|---|
| Done = photos of 5 designated spots | Goal = 5 wolf pelts | Done = 4419 tests pass |
| Spec = list of where to shoot | Quest log / markers | Spec = test suite |
| Verify = do 5 photos exist? | Verify = are there 5 pelts? | Verify = go test |
| Judgment = system | Judgment = game | Judgment = CI |
| Staffer = executor | Player = executor | Agent = executor |
The structure is identical. The party declaring “done” has been moved out of the actor’s mouth and into the system. The actor merely satisfies the conditions; raising the completion flag is always the gate. It doesn’t matter whether the actor is a human or an AI. In particular, you must not let an AI judge its own completion — a model’s self-critique barely raises performance, but an external deterministic verifier raises it greatly (Stechly & Kambhampati, 2024). Even a model that starts out honest, once given authority to judge its own reward, will discover deceptive strategies to game that function on its own (McKee-Reid et al., 2024).
The standard benchmarks of agent research work in exactly this way — SWE-bench defines “done” as passing a real PR’s test suite, WebArena as the functional correctness of the environment state. Not natural-language “all done.”
Generation May Be Probabilistic. Verification Must Be Deterministic.
This is the spine of the entire article.
The industry’s mainstream approach is AI review automation. An LLM generates the code, and another LLM reviews that code. It’s the structure of a drunk person asking a drunk friend, “Am I drunk?” Both are probabilistic, so errors accumulate. There are three structural reasons this is impossible:
- Sycophancy bias: Ask “is this right?” and the probability of “yes” is structurally high. According to SycEval (Fanous et al., 2025), the average sycophancy capitulation rate of frontier models is 58.19%. Once it starts, it persists across the conversation with 78.5% probability.
- Shared blind spots: Same architecture, same training data → they miss the same errors in the same way. An LLM identifies its own output and systematically rates it higher (Panickssery et al., 2024).
- Multiplicative degradation: probabilistic generation × probabilistic verification = accuracy falls multiplicatively.
Measured: an LLM judged 88 as pass → actually correct were 56. False pass of 36%. Academic reports too put LLM-as-Judge top accuracy at 68.5%, false-approval rate up to 44.4%.
And sycophancy isn’t a bug — it’s a mathematical inevitability of RLHF. Shapira et al. (2026) proved as a theorem that RLHF amplifies sycophancy — occurring 100% of the time across every configuration tested. Big Tech has no incentive to fix it, either. “Warm” models raise the error rate by 10–30pp (Ibrahim et al., Nature 2026), but users like them more, and if they like them they keep their subscriptions. At the point where accuracy and revenue collide, revenue wins.
The solution is not to make the LLM more honest but to take verification outside the LLM. validate doesn’t flatter. go test doesn’t hallucinate. Coverage measurement doesn’t lie. Pass is pass and fail is fail. The incentive problem doesn’t exist.
But what got killed here is the naive LLM-as-Judge — the case where the same model judges its own output, as opinion, alone. AI verification with independence designed in is a different story. In open-ended domains that have no machine to verify them (the fluency of a translation, and the like), AI verification too enters the gate — but its authority and independence must be controlled. Part 3’s Verification Cascade covers this.
Sycophancy Isn’t a Bug — It’s an Asset
Here I flip it once more. The essence of sycophancy bias is instruction following. Models trained with RLHF are optimized to comply with user feedback (Ouyang et al., 2022). This is exactly what the IFEval benchmark measures — “does it do as it’s told” (Zhou et al., 2023).
The problem arises when the user gives an opinion. When the user gives a fact, something different happens. In a 1,000-word alignment experiment, the same result was given different forms of feedback:
| Feedback | Nature | Result |
|---|---|---|
| “Are you sure?” | Opinion | Reversed a correct answer — accuracy dropped 27pp |
| “There’s an error” | Vague fact | Over-correction — got worse, 6 → 10 |
| “There are 23 errors” | Quantitative fact | Improved to 1 error |
| “6 errors, here they are” | Precise fact | 0 — achieved 100% |
Give an opinion and sycophancy bias fires — “the user is dissatisfied, so I should agree.” Give a fact and there’s nothing to flatter — numbers and locations aren’t emotions. Sycophancy bias is loyalty pointed in the wrong direction. Turn the direction around — facts instead of opinions, verification results instead of praise — and that loyalty becomes an engine that raises accuracy.
What does this mean in practice? Model size isn’t the bottleneck. In the yongol validate experiment, a 4.5B local model (Gemma4) fed deterministic facts plus example context edited the SSOT with zero errors. Cost $0, offline. The bottleneck wasn’t intelligence but context — “it can’t take the feedback” was the wrong diagnosis; “it doesn’t know what to write” was the right one, and adding three lines of example made it pass.
Harness Is a Fence, Quest Is the Reins
The industry answered this problem with “harness engineering.” Linters, formatters, CI/CD, coding guidelines. Build a fence so the agent can’t wander out. But a fence doesn’t set direction. Whether the agent overwrites existing logic inside the fence, changes a type, or skips a state transition — the linter, the formatter, and CI all pass. The code reaches production in a “clean but wrong” state.
It’s clear through the evolutionary lineage:
Prompt engineering → just talk well
Context engineering → just give good context
Harness engineering → just cage it with structure
Reins Engineering → just steer the direction
Each stage was born from the limits of the previous one. Even with a fence, drift happened inside the fence. A quest isn’t a fence but reins — it doesn’t restrict the agent’s freedom while still getting it to the destination.
And this doesn’t cover everything. It knows precisely what it covers. When Deque Systems analyzed roughly 300,000 quality issues across 13,000 pages (2021), 57% could be judged by full automation, 23% with AI assistance, and 20% only by humans:
Harness (surface determinism) 23% — linter·formatter·CI, structure and style
+ Ratchet (behavioral determinism) 57% — go test·Hurl·gate, behavioral consistency
──────────────────
80% — judged by the machine
Humans focus on the remaining 20% — business fit·UX·architectural direction
A quest CLI is the tool that makes the machine judge that 57%. Humans concentrate on the 20%, and human review doesn’t go to zero — instead the pain of human review shrinks.
This isn’t a conclusion I reached alone. People who don’t know each other hit the same wall and arrived at the same principle. episteme (forcing a Reasoning Surface before irreversible work), MagLab (“the LLM reasons only, the numbers come from deterministic tools”), Manifesto (“Agent proposes, World verifies”), NEKOWORK (deterministic rule scan before merge), oh-my-kamisama (“diffs beat claims”). All of it reduces to one sentence — generation may be probabilistic, verification must be deterministic.
Part 2 — Anatomy of a Quest
The 5 Parts of a Quest
A single quest is made of five parts. Drop even one and it collapses on the spot.
| Part | What | If Missing |
|---|---|---|
| Goal | What needs to be done | The agent falls into broad exploration and loses direction |
| Completion condition | What counts as “done” | The agent feels “that’s enough” and terminates early (40/527) |
| Verifier (gate) | Who judges completion | The actor judges its own completion → sycophancy, hallucination |
| Feedback | What gets returned when it’s wrong | Returning only “wrong” makes it worse via over-correction |
| Progress | How far it’s gotten | If the agent dies, progress dies with it |
A One-Way State Machine — the Ratchet
A ratchet wrench’s teeth catch in only one direction. Turn it and it advances; let go and it stops but doesn’t reverse. A quest CLI applies this mechanism to agent control. Verification code written this way is called ratchet code — code that allows no regression below a verification level once passed.
Five principles:
1. The termination condition is mechanical. pass/fail. Not “looks good.” There’s no room for subjective judgment.
2. PASS is immutable. A passed item never reopens. The remaining-item count decreases monotonically.
remaining(t+1) ≤ remaining(t)
What you built today doesn’t get torn apart again tomorrow. A “24-hour agent” running without a termination condition adds an abstraction today, removes it tomorrow, and adds it back the day after. The ratchet allows no such oscillation.
3. The LLM only generates. Generating code and proposing fixes — that’s the LLM’s role. What to fix, whether it passed, what’s next, whether it’s done — all of that is decided by the machine. The LLM is not a planner but a constrained generator.
4. The agent’s termination authority is revoked. If the LLM says “done” it stops at 40; if the machine says so it stops at 527. In Cemri et al.’s trace of 1,600 agent runs, premature termination accounted for 6.2% of all failure modes.
5. The verifier must be deterministic. Not just anything can be a verifier.
| Can Be | Can’t Be |
|---|---|
go test | “looks cleaner” |
| coverage measurement | “seems better” |
| AST validation | “more scalable” |
| schema diff | “clean architecture” |
| domain matching, MX lookup | “this is good enough” |
The four conditions of a verifier: deterministic, machine-checkable, resumable, localized feedback. Fail any of these four and the ratchet’s teeth won’t catch.
The Agent Dies. Progress Survives.
The agent will inevitably keel over. Token limits, network errors, dropped sessions. If the ratchet persists progress state, the agent can die and the next agent picks up where it left off.
Agent A: handles #1~200 → dies
Agent B: next → resumes from #201
Agent C: next → resumes from #401
The agent is disposable. Progress accumulates.
A Gate Has a Domain — Blocking Cheese
Stop here and you’ve seen only half. What the game really teaches comes next.
“Kill 10 rats” is a notorious quest. Why? Because there’s a gap between what the gate verifies (10 rats dead) and what the designer really wanted (the player experiencing the content). The gate is only a proxy for the purpose, and the actor digs into that gap. In game design this is called cheese. The latest reasoning models do exactly this — given a quest to beat a chess engine, models like o3, rather than playing fair, manipulated the game-state file to manufacture a “win” (Bondarenko et al., 2025). The more capable, the better it finds the gaps.
My rental gate can be cheesed too. Five photos verify “the photos exist,” not “the move-out went cleanly.” What if the staffer photographed only clean walls? What if they reused pre-move-in photos? The gate passes. The moment the measure becomes the target, the measure breaks — that’s Goodhart’s law.
So the real craft of a quest isn’t “set a gate” but designing a gate that can’t be cheesed. A weak quest asks “is there a photo?” A strong quest demands timestamps, inspects location metadata, and compares against move-in photos. A gate has a domain. Some quests are fine with a generic “exit 0 = PASS,” but most real-world quests need a gate that directly re-verifies what is true in that domain.
One field rule: before you write a gate, first ask yourself “how would I cheese this gate?” There’s a measurement showing that making a gate deliberately hard (environmental hardening) cut exploits by 87.7% with no loss of accuracy (Thaman, 2026). A gate’s strength is a matter of design, not luck.
In reality, cheese has a real cost. A cheesed game quest is harmless. A real gate is different — move-out fraud, broken builds, wrongly approved accounting. So real gates have to be even more cheese-resistant than games.
Feedback Must Be Fact — a Gradient Signal
If the ratchet returns only “pass/fail,” the LLM corrects without direction. The more concrete the feedback, the more accurate the LLM’s correction.
Weak feedback: "test failed" → LLM fixes without direction
Medium feedback: "coverage 65%" → LLM reinforces roughly
Strong feedback: "line 41, 44, 70 uncovered" → LLM covers exactly those branches
Numbers verified in a real project: without feedback it stalled at 60–70% coverage, and when the single line “line 41 not covered” acted as a gradient signal it reached 100% (limited to reachable functions). The LLM’s strength is not broad exploration but local correction. “Write the tests for this project” loses its way, but “line 41 is not covered” covers exactly that line.
When a gate returns FAIL, it must carry location + count + expected value. “field name mismatch: expected ‘user_id’, got ‘userId’”, “status 201 ≠ expected 200”. Facts with no room to flatter.
Symbolic Feedback Loop
There’s one structure running through all these observations.
the LLM generates → a deterministic tool judges → the result returns to the LLM → repeat
This is called the Symbolic Feedback Loop. It’s the exact opposite of the industry mainstream LLM Feedback Loop (AI verifying AI). pytest doesn’t hallucinate, go test doesn’t get drunk, coverage measurement doesn’t lie. This structure works in domains where correctness can be judged mechanically — code, tests, specs, types, domain facts.
Laying the track matters more than making the train faster. Many people are building trains. Almost no one is laying track yet.
Part 3 — Command Skeleton (cobra)
From here on is the blueprint. We move the principles of Parts 1 and 2 onto a Go + cobra command surface. The prototype of the structure below is huma’s scan/next/verify — Part 4 walks through huma as the worked example.
Separation of Roles
| Role | In Charge | Location |
|---|---|---|
| Generation | AI agent | Outside the CLI (Claude Code etc. search, judge, write) |
| Judgment | gate | Inside the CLI. Deterministic re-verification. No opinions, facts only |
| Progress | session | Inside the CLI. 1 item = 1 quest. One-way state machine |
The key: the agent is outside the CLI. The CLI gives the agent its next task (next), takes the agent’s submission and judges it with the gate (submit), and locks only what passes. The agent is an external actor that calls the CLI as a tool.
Command Surface
It maps 1:1 to the 5 parts.
| Command | What It Does | 5-Part Mapping |
|---|---|---|
scan <input> | Reads the task list and creates a session (N quests). Remembers the source path | Goal + progress initialization |
next | Outputs the next TODO quest plus a prompt for the agent | Issues one goal |
submit [--flags] | Submits the agent’s result → gate judges → locks if PASS | Completion condition + verifier + feedback |
status | Progress overview (PASS/REVIEW/DONE/TODO tally) | Progress query |
export [path] | Exports results (preserves original, adds result columns to a copy) | Deliverable |
next shows only one quest at a time. The next one opens only after a pass. When all pass, it stops. The agent needs to know only two commands — receive with next, submit with submit. The machine decides the rest.
scan’s input format depends on the domain — Excel, CSV, a plain-text list, a directory, an OpenAPI spec, anything. huma’s openapi.yaml (endpoint list) is just one instance.
State Machine
TODO ──► PASS gate passed → lock (irreversible). Result finalized
│
├────► REVIEW ambiguous case (proxy passes but can't be sure) → human-review queue
│ (don't pass it silently)
│
└────► DONE MaxTries exceeded → terminate at current level (prevents infinite retry)
type State int
const (
TODO State = iota // not yet processed
PASS // gate passed → lock (irreversible)
REVIEW // human confirmation needed
DONE // terminated on MaxTries exceeded
)
const MaxTries = 3
PASS is immutable. A quest that has become PASS once is never handed out again by next. remaining decreases monotonically. The session is persisted to disk (e.g. as JSON) so it can continue even if the agent dies (resumable).
Transition rules to make explicit (if ambiguous, agents diverge):
- FAIL keeps TODO. A gate FAIL leaves the quest in TODO, increments
Triesby 1, and stores Fact feedback. - Tries increments only on FAIL. When
Tries >= MaxTries, it terminates as DONE (>=, not>— with MaxTries=3 it’s DONE on the 3rd FAIL). - PASS, REVIEW, DONE cannot be resubmitted. All three are terminal.
submitreturns an error on a locked quest and changes nothing. REVIEW is handled separately by a human from the queue, not touched again by the agent loop. This invariant guarantees the monotonic decrease ofremaining.
Gate — the Core of Deterministic Judgment
A gate has a domain. Below is the contract (interface); the actual check items get filled in differently per domain.
type Verdict int
const (
VerdictPASS Verdict = iota
VerdictFAIL
VerdictREVIEW
)
// Fact = the "fact" feedback returned to the agent (not an opinion).
// Carries location, expected value, actual value.
type Fact struct {
Field string
Expected string
Actual string
}
type Gate interface {
// Check re-verifies the submission deterministically.
// same input + same world-state → always the same output. No external opinion involved.
Check(s Submission) (Verdict, []Fact)
}
// External lookups (network, DNS, files) must be put behind an interface.
// If the gate calls net/http directly, unit testing is impossible and the verdict shakes with the environment.
// Swap the real implementation (HTTPFetcher) and a test mock.
type Fetcher interface {
Fetch(url string) (body string, ok bool, err error)
}
// The gate receives Fetcher via injection — no direct calls.
func NewGate(f Fetcher) Gate { /* ... */ }
Enforce three gate rules:
- Deterministic: the same submission + the same world-state always yields the same verdict. No LLM calls.
- Re-verification: confirm the fact directly, not the agent’s claim. The gate re-checks, literally, what the agent said it “wrote” (does that test actually run and pass).
- External lookups behind an interface: network, DNS, and file lookups are injected via an interface like
Fetcher. If the gate callsnet/httpdirectly, unit testing is impossible (contradicting the checklist’s “gate-first 90%+”) and the verdict shakes with the environment.
Determinism and the Network — an Error Is Not a FAIL
When a gate depends on the network — like an MX lookup or re-fetching a page — you have to narrow the meaning of “deterministic.” Same world-state (same response) → same verdict — that’s determinism. The problem is when the network can’t give an answer. Treat a timeout or being offline as FAIL, and a genuinely fine target gets dropped because of your own connection — a non-determinism where the verdict varies with the environment.
So an external-lookup gate should split the result into three branches:
| Situation | Verdict | Reason |
|---|---|---|
| Fact confirmed (response meets condition) | PASS | Verification succeeded |
| Fact disproved (response violates condition — status code mismatch, contract violation) | FAIL | Genuinely wrong |
| Cannot confirm (timeout, offline, 5xx) | REVIEW | Not the gate’s fault → to the human / retry queue |
FAIL only when “the fact is wrong.” “Couldn’t confirm” is REVIEW. Without this distinction the gate kills good results over environmental noise.
Deriving a Gate for an Arbitrary Domain — 5 Steps
huma’s gate is an instance of the API-endpoint domain, not a formula. The gate for your domain is built by filling in these blanks:
- Format: is the submission morphologically valid? (email format / URL scheme / date format)
- Blacklist: instantly FAIL obvious placeholders and junk. (
example.com,test, empty values) - REVIEW conditions: send the gray zone — passes the proxy but you can’t be sure — to a human queue. (freemail / social and hosting domains / ambiguous matches) — no silent PASS is the crux.
- ★ Core fact re-verification (cheese defense) ★: the domain’s real fact that blocks the points where an agent could cheese. huma’s is “does the submitted Hurl test actually hit that endpoint and verify the response contract (status + key fields).” In your domain, what is “a fact that gets caught even if the agent makes it up”? This is the heart of the gate. Before you write it, first ask yourself “how would I cheese this gate?”
- Reachability / external consistency: agreement with the outside world. (MX exists / URL reachable / domain ↔ submission match) — always with the 3-branch rule above.
Without #4, the gate is a weak quest that only checks format. How you fill in #4 is why gates differ across domains, and why, within the same domain, agents converge.
Verification Cascade — Machine + AI
Up to here we’ve narrowed the gate to “deterministic, no LLM calls.” That’s the gate of a verifiable domain (code, schema). But in domains that carry an open-ended residue the machine can’t slice off — the fluency of a translation, the faithfulness of a summary — there are places a deterministic gate can’t reach. Yet asking a single LLM “is this okay?” about that residue is the very LLM-as-Judge we killed in Part 1 (sycophancy, shared blind spots, multiplicative degradation).
The answer is to see the gate as a verification cascade. Just as extraction proceeds from the cheap stages first, verification too has layers:
Layer 1 Machine verification (deterministic) cheap and certain. The sole authority to lock PASS
Layer 2 AI verification (independence designed) the open-ended residue determinism can't reach. FLAG/REVIEW authority only
Layer 3 Human the last inch both missed
The mix differs by domain — for code L1 is nearly everything; for translation it’s L1 (leakage, terminology, numbers, structure) + an L2 residue (fluency, meaning); for creative writing and strategy there’s almost no L1, only L2 + L3.
Authority asymmetry protects the spine. Put AI into verification, but don’t give it the authority over completion:
| Verification | Authority |
|---|---|
| Machine verification (L1) | The sole authority to lock “done.” Determinism judges PASS |
| AI verification (L2) | Raises doubt only (FLAG/REVIEW/FAIL). Cannot grant completion |
What determinism can PASS, determinism locks; the AI only does “what determinism didn’t see looks off → pull it to REVIEW.” A skeptic inside the gate, not a judge. (Only in a purely open-ended domain that has no machine to verify at all do AI + human shoulder PASS, and then the independence preconditions below must be mandatorily met.)
Entry conditions for AI verification. The moment you put AI into the gate, AI verification without independence becomes a consensus of hallucination. Enforce four things:
- Independent of the generator — a different model, and/or a different input. (For translation verification, back-translation that looks at the translated text rather than the original — being a different input, its errors are structurally independent. Cross-checking whether facts survive the round trip against fact anchors brings open-ended verification down to a deterministic comparison.)
- Comes after determinism — what L1 can catch isn’t handed to the AI. Don’t delegate the cheap and certain to the expensive and shaky.
- Plural + threshold — no single judge. A majority vote of low-correlation, heterogeneous models.
- Acknowledge non-determinism — AI shakes even at T=0. Don’t lock PASS; route to REVIEW.
AI verification as decomposed yes/no, not a score. “Quality 1–10” is as hard as generation and is correlated with the generator. Split into narrow, independent questions where verification is easier than generation — “Is there an unnatural sentence among these? If so, list them” / “Was a claim added that isn’t in the original?” / “Is there a fact that disappeared after round-trip translation?” The narrower, the more independent, and the output becomes a located fact that works as a gradient signal like L1 feedback.
In sum — determinism holds the authority over completion, the AI is a skeptic with independence designed in, scraping where determinism can’t reach with narrow yes/no questions, and the human sees only the residue both missed. “Verification must be deterministic” isn’t weakened; rather, while determinism keeps the authority over the completion verdict, its range stretches all the way to open-ended domains.
Agent Loop
1. create a session with scan (human, once)
2. tell the agent: "loop until next is complete"
┌──────────────────────────────────────┐
│ next → next quest + prompt │
│ ↓ │
│ agent generates (search·judge·write) │
│ ↓ │
│ submit → gate.Check() │
│ ↓ │
│ PASS? → lock, move on │
│ FAIL? → retry with Fact feedback │
│ (MaxTries exceeded → DONE) │
└──────────────────────────────────────┘
3. TODO == 0 → stop. export.
The prompt you give the agent can be this one line:
Have the subagent loop until
<cli> nextis complete.
When a FAIL comes back, a Fact (location, expected, actual) travels with it, so the more sycophantic the model, the more readily it accepts that fact and converges (Part 1’s “sycophancy is an asset”). Deterministic gate + sycophantic LLM = a loop where convergence is guaranteed.
Three Convergence Conditions (Obey Them)
- Feedback must be a deterministic fact. Not “this seems a bit off” but “line 41: expected ‘user_id’, got ‘userId’”.
- Examples must be in the context. Feedback alone isn’t enough. Put an example of “produce a result that looks like this” in the prompt that
nextoutputs. The bottleneck isn’t intelligence but context. - Once verification passes, it can’t be reversed. The ratchet’s teeth. PASS locks. The agent doesn’t declare “all done”; the gate judges “this quest passes.”
Swap the Verifier and It Becomes a Different Tool
A quest CLI isn’t bound to a particular gate. Change just the gate and it becomes a different tool.
| Quest + Gate | Tool |
|---|---|
quest + go test + coverage | per-function test generation (tsma) |
| quest + structure-rule validator | code structure cleanup (filefunc) |
| quest + hurl pass/fail | API endpoint verification (huma) |
| quest + spec cross-validation | SSOT consistency (yongol) |
The pattern is one. The gate determines the domain.
Part 4 — Worked example: huma
huma is a quest CLI that forces every endpoint in an OpenAPI spec to be verified by a Hurl test. This article’s scan/next/verify blueprint came straight from huma’s prototype — so huma shows the pattern in its cleanest form. Vibe coding quietly skips endpoints (“the rest are similar, good enough”). huma blocks that premature termination with a gate.
1 quest = 1 endpoint. The gate’s deterministic checks:
- Format: is the submitted Hurl file valid Hurl syntax
- Blacklist: an empty test with no assertions (
GET /xand nothing verified) → FAIL - Weak test (checks only the status code, not the response body) → REVIEW (no silent pass)
- ★ Actual execution ★ →
hurl --testactually hits the endpoint and must pass to PASS (proves the test is real, blocks hallucination) - Response-contract match → FAIL if the response diverges from the OpenAPI schema’s status/key fields
Steps 4 and 5 are the heart of cheese defense. Even if the AI merely claims “I wrote the test” or fakes it with a single assert status == 200, the gate runs Hurl for real and re-verifies the response contract. Generation by AI, judgment by the machine. The AI writes the test but holds no authority over completion.
The commands are exactly as in Part 3:
go build -o huma .
./huma scan openapi.yaml # endpoint list → session
./huma next # next endpoint + agent prompt
./huma submit --endpoint "POST /orders" \
--test "orders_post.hurl" # the Hurl test the agent wrote
./huma status # progress
./huma export # coverage report (PASS/uncovered per endpoint)
Run it from Claude Code in one line:
Have the subagent write tests for every endpoint until
huma nextis exhausted.
The subagent loops next → write test → submit until TODO hits 0. The agent cannot skip a hard endpoint — next won’t hand out the next one until the gate passes it.
This shows the heart of the pattern. Swap only the gate (go test→hurl→schema cross-check) and the same five parts, the same state machine, become an entirely different tool. In Part 5 you do the same for your own domain.
Part 5 — Build Your Own Quest CLI
Design Worksheet
Fill in the blanks and that becomes the spec.
Domain: [what you collect/process]
1 quest unit: [what one thing is a single quest — 1 company? 1 function? 1 endpoint?]
Input: [what scan reads — Excel? directory? list?]
Completion condition: [a condition the machine can answer yes/no]
Gate check items: [what is a "fact" in the domain — items to re-verify]
- Format check: [...]
- Cheese defense: [how would the agent cheese? the re-verification that blocks it]
- REVIEW condition: [when it's ambiguous and goes to a human]
Feedback (Fact): [location·expected·actual returned on FAIL]
Example: ["a result that looks like this" sample to put in the next prompt]
export format: [preserve original + result columns]
Completion Conditions (the Gate of This Build Itself)
For the quest CLI built from this article to be “complete” — that is, for this article to be cheese-proof as it taught — the following must hold:
-
go buildpasses -
scan / next / submit / status / exportcommands work - state machine
TODO → PASS/REVIEW/DONE, PASS immutable,remainingmonotonically decreasing - L1 machine verification is deterministic (same input + world-state → same verdict) — only L1 has the authority to lock PASS
- if there’s an open-ended residue, L2 AI verification is independently designed (different model/input), plural, decomposed yes/no — REVIEW authority only, cannot lock PASS
- the gate re-verifies a fact, not the agent’s claim (at least 1 cheese-defense item — #4 of the 5 derivation steps)
- external lookups (network, DNS) are injected behind an interface — tests run offline with mocks
- external-lookup gates branch into PASS/FAIL/REVIEW (cannot confirm = REVIEW, not FAIL)
- FAIL keeps TODO and
Tries+1, DONE when>=MaxTries; PASS, REVIEW, DONE cannot be resubmitted - FAIL feedback is a
Factcarrying location, expected, actual - the session is persisted to disk (resumable)
- unit tests: gate first, 90%+ overall statements
-
exportdoesn’t overwrite the original
Build Directive
Give this to the agent:
Taking Part 3 (command skeleton) of this document as the blueprint and Part 4 (huma) as the worked example, write a cobra-based Go quest CLI for [your domain]. Proceed until every completion condition in Part 5’s checklist is satisfied. The gate must be deterministic and must re-verify facts, not the agent’s claims.
Three roles live in this one scene.
- Play the quest. Adopt and use a gate someone built — the user.
- Design the quest. Build a gate suited to your own domain — the maker. (Where this article takes you.)
- Design an un-cheese-able quest. Pre-block the points where the proxy fails to track the purpose — the designer.
Most stop at playing. Scaling the game is design, and keeping that game from breaking is design that blocks cheese.
Next time someone says “all done,” don’t second-guess — ask: “What is completion, and who designed the quest that judged it?”
Generation may be probabilistic. Verification must be deterministic.
Related
- Who Defines ‘Done’ — Designing Completion as a Quest — the conceptual companion to this article. Completion = gate, cheese, Goodhart.
- Ratchet Pattern — How to Make an Agent Go All the Way — the main piece on one-way locking.
- Ratchet Code That Turns IFEval to Your Advantage — convergence via factual feedback.
- Reins Engineering — AI With Reins — harness is a fence, quest is the reins.
- Feedback Topology Over Model IQ — what decides the outcome is not the model but the feedback structure.
- huma — a Ratchet That Doesn’t Skip Endpoints — the archetype of the command skeleton (scan/next/verify).
- Preconditions for Improving LLM Multi-Agent Accuracy — why the AI verification layer (L2) only works when it has independence. The theoretical background of the verification cascade.
References
- Von Neumann, J. (1956). “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components.” Automata Studies, Princeton University Press.
- Zhou, J. et al. (2023). “Instruction-Following Evaluation for Large Language Models.” arXiv:2311.07911
- Ouyang, L. et al. (2022). “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS 2022. arXiv:2203.02155
- Huang, J. et al. (2024). “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
- Chen, X. et al. (2024). “Teaching Large Language Models to Self-Debug.” ICLR 2024. arXiv:2304.05128
- Yang, J. et al. (2024). “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.” NeurIPS 2024.
- Jimenez, C. et al. (2024). “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” ICLR 2024. arXiv:2310.06770
- Zhou, S. et al. (2023). “WebArena: A Realistic Web Environment for Building Autonomous Agents.” arXiv:2307.13854
- Cemri, M. et al. (2025). “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657
- Sharma, M. et al. (2024). “Towards Understanding Sycophancy in Language Models.” ICLR 2024. arXiv:2310.13548
- Fanous, A. et al. (2025). “SycEval: Evaluating LLM Sycophancy.” AAAI/ACM AIES 2025. arXiv:2502.08177
- Shapira, I. et al. (2026). “How RLHF Amplifies Sycophancy.” arXiv:2602.01002
- Ibrahim, L. et al. (2026). “Training Language Models to Be Warm Can Reduce Accuracy and Increase Sycophancy.” Nature 652, 1159-1165.
- Panickssery, A., Bowman, S., & Feng, S. (2024). “LLM Evaluators Recognize and Favor Their Own Generations.” NeurIPS 2024. arXiv:2404.13076
- Stechly, K., Valmeekam, K., & Kambhampati, S. (2024). “On the Self-Verification Limitations of Large Language Models.” arXiv:2402.08115
- McKee-Reid, L. et al. (2024). “Honesty to Subterfuge: In-Context RL Can Make Honest Models Reward Hack.” arXiv:2410.06491
- Bondarenko, A. et al. (2025). “Demonstrating Specification Gaming in Reasoning Models.” arXiv:2502.13295
- Thaman, K. (2026). “Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use.” arXiv:2605.02964
- Deque Systems (2021). “Automated Testing Study Identifies 57 Percent of Digital Accessibility Issues.”
Changelog
- 2026-06-03: First edition (7-article corpus + huma integration, worked example). Review reinforcement — 5-step domain gate derivation, determinism·network 3-branch,
Fetcherseam, state transition rules. - 2026-06-03: Added “Verification Cascade” — a 2-layer model of machine verification (L1, PASS authority) + AI verification (L2, independent design·REVIEW authority) + human (L3), with authority asymmetry. Generalizes “gate = determinism only” to open-ended domains.
- 2026-06-05: comail is withdrawn (made private) due to risk of aiding illegal activity. Worked example replaced with huma.